Az egyéni hangszínezet és a beszélő felismerésének kísérleti-fonetikai megközelítése*
Bevezetés
Ha hallunk egy szót, annak akusztikai hullámformája a fülön keresztül a hallóközpontba jut, majd a Wernicke-területre kerül, ahol a hangsor, majd annak szemantikai tartalma feldolgozódik. Egyúttal számos más döntéssorozat is történik agyunkban. Ha a szót egy számunkra jól ismert személy ejtette ki, akkor képesek vagyunk ezt a személyt azonosítani. Ez azonban nem mindig ilyen egyszerű, a sikeres felismerés csak bizonyos korlátozásokkal működik. Sokszor nem elegendő egyetlen szó, hogy felismerjünk valakit, máskor pedig a telefonvonalnak az élőszónál jóval szűkebb frekvenciatartománya is lehetővé teszi, hogy azonosítsuk, ki van a vonal másik végén.
Az elmúlt évtizedek alatt a fonetikával, illetve beszédakusztikával foglalkozó szakemberek alapos és kimerítő vizsgálatokat végeztek a beszédelemzés legtöbb területén (vö. Stevens 1998). Sikerült akusztikai elemzéssel mintegy rekonstruálni a beszédet, sőt – bizonyos korlátokkal – beszédfelismerő rendszerek is működnek. Azzal a ténnyel azonban, hogy az emberi hang magában rejti az egyéni jellemzőket is, csak az utóbbi évtizedekben kezdtek behatóan és körültekintően foglalkozni. A kiinduló kérdés az volt, hogy a beszéd szegmentális vagy szupraszegmentális részében keresendő-e az egyéni hangra utaló összetevő, vagy mindkettő tartalmazza azt.
Ahhoz, hogy valakit felismerjünk a hangja vagy a beszéde alapján, már többször hallanunk kellett őt. Minél „jellegzetesebb” valakinek a hangja vagy a beszédmódja, annál könnyebb a felismerés. Még a jól ismert személyt sem tudjuk azonban minden körülmények között biztosan azonosítani. Az azonos nemű testvérek, az apa és a fiú vagy az anya és a lánya könnyen összetéveszthetők, ha a körülmények nem tekinthetők ideálisnak, például rövid közlést mondanak, zajos környezetben vagy telefonban beszélnek.
A probléma elméleti aspektusa az emberi hangszínezet kérdéskörében gyökerezik. Milyen mértékben jellemző az emberre a hangja, illetőleg a beszéde? Miképpen határozható meg az egyéni hangszínezet? E kérdéshez azután számos további kapcsolódik. A hangszínezet mely beszédképzési konfigurációval mutatja a legszorosabb kapcsolatot? A zönge, a toldalékcső avagy az artikulációs mozgások a meghatározóak, avagy valamennyi együtt eredményezi a hangszínezet nyújtotta percepciós élményt? Miként fejezhető ki a hangszínezet: artikulációs, akusztikai-fonetikai, percepciós-fonetikai megközelítésben avagy mindháromban együtt? A mindennapi életben jól ismert kifejezések, amelyek a beszélő hangszínezetét igyekeznek meghatározni, általában metaforák: bársonyos hang, borízű hang, lágy hang, érces, érdes hang, sipító hang, rekedtes hang, fátyolos hang, „barna” hang, éles hang, dörgő hang, csengő hang, megnyugtató hang, bántó hang, sőt „úgy beszél, mintha gombóc lenne a torkában”, és még lehetne folytatni.
Mi áll ezeknek a kifejezéseknek a hátterében a fonetika szempontjából? Mielőtt megpróbálkoznánk a válasz megkeresésével, szembekerülünk a szakszó használatának problémájával is. Mára már kimondható, hogy a hangszín szót a beszédhangok jellemzésére, míg a hangszínezet szót a beszélő személy beszédének jellemzésére használjuk. A hangszínezet része annak a sajátos és összetett jelenségnek, amelynek hatására képesek vagyunk a beszélő személyt azonosítani. Az angol nyelvben például ennek az összetett jelenségnek a megnevezésére a hangminőség (voice quality) kifejezést használják (Crystal 1985). (A magyar terminológia nem egységes; a hangminőség bizonyos szövegkörnyezetben a beszédhangra is vonatkozhat, ugyanakkor a hang szó ’Stimme’ értelemben is használatos, vö. Vértes O. 1979.) Bár a hangszínezet önmagában nem fedi le azt a komplex jelenséget, amely a beszélő személy felismerését lehetővé teszi, jobb híján mégis ezt a terminust fogjuk használni – jelentésének kiszélesítésével – azért, hogy egy újabb szakszó bevezetését elkerüljük. Ebben a szélesebb értelemben a hangszínezet magában foglalja mindazokat a beszédjellemzőket, amelyek egy adott személyt kétséget kizáróan azonosítanak. Az alaphangmagasság döntő tényezője a hangszínezetnek. Vértes O. András feltételezi, hogy az utóbbi évtizedekben (esetleg azt megelőzőleg is) a nők hangfekvése mélyült (ez kapcsolatba hozható társadalmi pozíciójukkal is), de a férfiaké nem változott (1979). Lux Gyula, korát sok tekintetben meghaladó könyvében (é. n., de 1926 után), azt állítja, hogy a hangszínkülönbség teszi lehetővé számára „atyja” és barátja hangjának felismerését (101).
Az énekművészettel foglalkozók már régen igyekeztek tudományosan alátámasztott magyarázatot találni a hangszínezet kérdéseire a mindennapi gyakorlati problémák megoldása érdekében. Az artikulációs gesztusok pontos leírásával azonosítottak némely hangszínezetet, például „világos” vagy „sötét”, illetőleg határoztak meg normálisnak és attól eltérőnek tartott hangszínezeteket (utóbbira: rekedtes, tompa, fedett, vö. Molnár 1942). A hangszín szón tulajdonképpen a zöngét értették; de ehhez kapcsolódva elemezték a préselt és az úgynevezett orrhangot is (Molnár 1942: 14–5). Vértes O. András történeti áttekintése szerint (1980) fonetikai munkában a hangszínezetről Regner Tivadar tesz először említést 1862-ben: a magyar nők mélyebb alaphangmagasságáról, valamint a bécsi német nyelvjárás rekedtes hangszínezetéről ír.
A probléma modern alkalmazott fonetikai megközelítése a fonetika egyik legújabb ágának, az úgynevezett törvényszéki fonetikának (forensic phonetics) a tárgya (ez a kérdéskör önálló diszciplínaként első ízben 1995-ben jelent meg a Fonetikai Világkongresszusok programjában). Ezek a kutatások a beszélő személy egyértelmű, kétséget kizáró felismerésének akusztikai-fonetikai megoldási lehetőségeivel foglalkoznak. Az utóbbi évtizedben jelentős eredmények születtek ezen a területen (Coulthard 1992; Schlichting–Sullivan 1998; a magyarra: Gósy–Nikléczy 1999). A megközelítések sokfélék, a matematikai számításoktól, az akusztikai méréseken át a szoros értelemben vett kísérleti-fonetikai és percepciós kísérletekig (pl. Schroder 1985; Nolan 1995). A beszélő felismerésének alkalmazott fonetikai vizsgálata azt a célt szolgálja, hogy meghatározhatóak legyenek azok a feltételek, amelyek a) lehetővé teszik, b) korlátozzák és c) nem teszik lehetővé/gátolják a beszélő személyének azonosítását. A tudománynak arra a kérdésre kell mindenekelőtt válaszolnia, hogy vajon a beszéd valóban olyan mértékben jellemző-e az egyénre, hogy az különféle célú azonosításokban (mint kriminalisztika, biztonsági rendszerek, beléptető vagy banki azonosító rendszerek) kétséget kizáróan működtethető. Amennyiben e kérdésre igenlő a válasz, a következő kérdéssorozat a beszélő azonosításának feltételeit, az azonosítás módszertani megoldásait és az azonosítás biztonsági fokának meghatározását érinti.
A központi kérdés tehát – függetlenül attól, hogy az egyéni hangszínezet elméleti igényű vagy a beszélőfelismerés alkalmazott fonetikai szempontú kutatásáról van szó – az, hogy melyek azok a paraméterek, amelyek kétséget kizáróan felidézik/meghatározzák a beszélő személyt.
A nem kriminalisztikai célú alkalmazásokban (pl. banki rendszerek) a beszélő felismerésének problémája – még telefonon át is – megoldottnak tűnik. A hetvenes évektől indultak meg az erre irányuló kutatások és fejlesztések (pl. Doddington et al. 1976), mára többféle, megbízhatóan működő rendszer létezik a világban. Némelyikük állítólag 99%-os biztonsággal képes a beszélő személy azonosítására. A kutatók különböző algoritmusok alkalmazásával vagy különféle többcsatornás szűrő eljárásokkal igyekeztek meghatározni a beszélő személy azonosságát. A kidolgozott eljárásokkal sikerült – technikailag jó minőségű rögzített beszéd esetében – 90% fölötti eredményt elérni, de a vizsgálathoz általában 40–50 s hosszúságú hanganyagra volt szükség. Ahhoz, hogy megértsük, miért megoldatlan probléma mégis a törvényszéki beszélőfelismerés, nézzük meg, mit jelent az egyén azonosítása a biztonsági rendszerekben. A beszélő valamilyen módon azonosítja önmagát (kóddal, névvel stb.), vagyis azonnal csökkenti a lehetséges bejelentkezők számát. A beszéd alapján történő személyfelismerésnek tehát arra kell válaszolnia, hogy valóban a feltételezett személy jelentkezett-e be. Egy többé-kevésbé meghatározott szöveget kell a beszélőnek bemondania (pl. szókapcsolatot, szókapcsolatokat vagy rövid mondatot). Általában az úgynevezett normalizált, hosszú idejű, átlagos spektrumelemzést használják, amelynek során az aktuálisan bemondott szöveg különféle jegyvektorait vetik össze a beszélőtől korábban tárolt szöveg paramétereivel. Ezt követően egy úgynevezett hasonlósági indexet számítanak. Az egyezést a küszöbértéktől való távolság szerint határozzák meg. Ezekben az esetekben tehát a beszélő felismerését számos tényező részben megkönnyíti, részben pedig kizárólagosan lehetővé teszi. A beszélő kooperatív, ez azt jelenti, hogy azt szeretné, hogy megtörténjen a biztos azonosítása. Létezik a beszélőtől már korábban tárolt, jó akusztikai és felvételi körülmények között rögzített beszédminta. Ismert az aktuális bejelentkezés körülménye, az összevetés tehát valóban gyorsan és jó hatásfokkal elvégezhető.
A törvényszéki esetekben a helyzet lényegesen bonyolultabb és bizonytalanabb. A beszélő személy ismeretlen, következésképpen nincsen „tárolt” beszédminta. Jó esetnek számít, ha van gyanúsított vagy gyanúsítottak, ez kiindulást jelenthet a személyazonosításhoz. A feltételezett eredeti beszélőnek azonban ekkor nem célja, hogy természetesen, tisztán, megfelelő hangerővel beszéljen; az akusztikai-fonetikai összevetés tehát nehezedik. Mintegy 15%-ra tehető ezekben az esetekben, hogy a beszélő akaratlagosan megváltoztatja a beszédét (Künzel 1995). A leggyakoribb ilyen torzítások a suttogás, a megemelt hangfekvés és a zárt szájjal képzett beszéd. A rögzített beszéd rendszerint zajos, szűk frekvenciatartományban jelentkezik, a hasznos paraméterek tehát erősen csökkentett számban vannak jelen (nemritkán csak 20–30 mp-nyi anyag áll az elemző rendelkezésére).
A leglényegesebb különbség a kétféle beszélőazonosítás között a lehetséges beszélők számának különbsége. Az egyik esetben tulajdonképpen a beszélő személyének igazolása történik meg; a kriminalisztikai esetekben pedig a valóságos azonosítás a cél. A beszélő azonosításához rendszerint háromféle megközelítésmódot használnak:
|
(i) |
hallás alapú elemzések (általában képzett szakemberek, elsősorban fonetikusok részvételével), |
(ii) |
akusztikai-fonetikai analízis széles sávú spektrogramok alapján, |
|
(iii) |
félautomatikus, speciálisan fejlesztett számítógépes elemző rendszerek alkalmazása. |
A hallás alapján történő azonosítás tulajdonképpen percepciós tesztsorozat, amikor a hallgató a rögzített beszédet igyekszik a feltételezett személlyel azonosítani (a hallgató emlékezetében tárolt minta alapján). A beszélő személyt nem ismerő lehallgatók a feltételezett egyezéseket próbálják meghatározni a rövid idejű memóriában tárolt beszédminták összevetésével. Mindkét esetben előfordulhat olyan feladat is, amikor – kizárásos alapon – azt kell megmondani, hogy melyik az a beszélő, aki biztosan nem azonosítható az eredetivel. A szakemberek olyan kérdésekre is tudnak valószínű választ adni, mint a nyelvjárás lehetősége, beszédhiba, a szociális háttér, iskolázottság, becsléssel az életkor, a beszédbeli jártasság. A fonetikus és nem fonetikus hallgatók beszélőazonosítási eredménye között nagy különbség is lehet. Köster (1987) azt találta kísérletében, hogy míg a fonetikusok 100%-ot értek el, addig a nem fonetikusok csak 89–94%-ot.
A beszélő felismerésének képessége
Az anyanyelv-elsajátítás folyamán kialakulnak azok a neurális spektrogramok az agyban, amelyek lehetővé teszik, hogy a gyermek a beszélő személy artikulációs sajátosságaitól függetlenül képes legyen a beszédhangokat azonosítani, a szavakat, mondatokat felismerni. Nem tudjuk még pontosan, hogy vajon ezek a neurális spektrogramok – mint ahogy megnevezésük sejteti – valóban hasonlatosak-e a beszédről készült akusztikai regisztrátumokkal, a spektrogramokkal. A spektrogramok mindig egyediek, a neurális spektrogramok pedig szükségszerűen valamiféle általánosított képek kell, hogy legyenek. Feltételezhetően a hangsor(ok)ra szignifikánsan jellemző invariáns jegyeket tartalmaznak, amelyek egyúttal információval szolgálnak a beszélő személyére vonatkozóan is. A kísérletek tanúsága szerint, néhány hónapos csecsemők képesek azonosítani az édesanyjukat a beszédük alapján akkor is, ha nem látják őket. Minél hosszabb az ugyanazon beszélőtől származó szöveg, a hallgató annál biztosabban képes a beszélőt felismerni. Ennek alapján az is feltételezhető, hogy a beszéd hallgatásakor aktiválódó neurális spektrogramsorozatban valamiképpen hangsúlyozottabbá válnak a beszélőt azonosító paraméterek. Ezek a feltételezések vezettek a matematikai megoldások kereséséhez, amelyek azonban nem hozták meg a várt eredményt.
A neurális spektrogramok kialakulásában az emlékezésnek meghatározó jelentősége van. Az emlékezés folyamatában a régebben észlelt tárgyak, jelenségek és események képét/képeit és ezek összefüggéseit felidézzük anélkül, hogy az azokat létrehozó ingerek vagy ingeregyüttesek éppen hatnának ránk. Az emlékezés az objektív valóságnak a tudatban történő visszatükröződése. Az emlékképek a múltbeli észlelések, élmények reprodukciói. A beszélő személy felismerésére vonatkoztatva két dolog alapvetően fontos: szükséges a megfelelő inger, valamint a felidézés képessége. Az észleletek, feldolgozott ingerek megjegyzéséhez az szükséges, hogy létrejöjjön az emléknyom, amely az ismétlések során bevésődik. Minél gyakoribb az ismétlődés, annál nagyobb mértékű a bevésődés. Ha ritkán hallunk valakit beszélni, lassabban, nehezebben azonosítjuk a beszédet a beszélővel. Minél gyakoribb a beszéd akusztikai élménye, annál gyorsabb és biztosabb lesz a beszélő személy felismerése.
Az emléknyomok felidézése többféleképpen történhet, általában valamiféle asszociáció révén. A felidézés alapja az a kapcsolat, amely bizonyos fokig már a bevésődéskor jelen van. Az asszociáció az emlékezésben azt jelenti, hogy a kialakult szinaptikus kapcsolatok működése révén az egyik emléknyom aktiválása egy vagy több hozzá kapcsolódó emléknyomot is aktivál. A beszédre vonatkozóan általános összefüggések is megfogalmazhatók. Nem véletlen például az alaphangmagasság és a testalkat, a hangszínezet és az arcforma vagy a beszédhang és az életkor kapcsolata (utóbbira: Gocsál 1998). Valószínűsíthető, hogy az emberek között nagy különbségek vannak a beszélő azonosításához szükséges képességek tekintetében; a beszélő személyének a beszéde alapján történő felidézéséhez az emberek asszociációs képessége különböző. Vannak, akiknél gyorsan történik a bevésődés, gyors a megfelelő neurális spektrogram aktiválása és ennek következtében a beszélő felismerése. Másoknál ezek a folyamatok lényegesen lassabban alakulnak ki, illetőleg mennek végbe.
Egyéni hangszínezet és a beszélő személy felismerése
A fentiekben az alapvető feltételt – a beszélő személy ismertségének megfelelő szintjét – már tárgyaltuk. A következő, egzaktan nehezen megfogható, ám a pszicholingvisztikában jól ismert tényezőt vesszük számba, az elvárás faktorát. Saját elvárásaink hatással vannak a beszélő személy sikeres felismerésére. Ha egy jól ismert személynek telefonálunk, rövid ideig egy hozzá hasonló hangú beszélőt is elfogadunk a kívánt beszélőül – az elvárás miatt. Ha várjuk valakinek a hívását, azonnal felismerjük, ha a vonal végén az illető megszólal. Ugyanennek a beszélőnek az azonosítása nehezebb, ha nem feltételeztük tőle a telefont. Kollégák beszédének 30 mp-es részletei elegendőek voltak ahhoz, hogy a személyek tökéletesen azonosíthatók legyenek (Ladefoged 1978).
A beszélőre jellemző neurális spektrogram nyilvánvalóan tartalmazza mindazokat a nyelvi/beszédbeli tényezőket, amelyek alapján azonosítjuk a személyt. A hatvanas, hetvenes évek nem túlzottan széleskörű kutatásai a beszédhangok akusztikai szerkezetében jelölték meg a meghatározó paramétereket. Elsősorban a magánhangzók harmadik formánsát gondolták jelentősnek, amelyről azóta egyértelműen bebizonyosodott, hogy nem is igazán jellemző, és messze nem elegendő az egyén azonosításához. Ha azonban csak egy formánst nézünk is (jelen esetben a harmadikat), akkor is három, numerikusan kifejezhető adattal állunk szemben: a formáns frekvenciaértékével, sávszélességével és az intenzitásával. Figyelembe véve azt az egyáltalán nem elhanyagolható tényt, hogy e három összetevő állandó változása a beszéd velejárója, akkor nehéz elméletileg is feltételezni azt a számértéket, amely az egyénre jellemző lehet. Ha pedig nem tudunk meghatározni egy vagy néhány konkrét frekvenciaértéket (maximum ±30 Hz eltéréssel), akkor a személyazonosítás számértékek alapján nem valószínűsíthető. Egyelőre még nem vettük figyelembe azt, hogy a formánsok értéke függ a hang hangkörnyezetétől is. Létezik olyan kutatási eredmény is (Hollien 1977), amelyik nemcsak a harmadik formáns jelentőségét kérdőjelezi meg, hanem azt is, hogy az egyéni hangszínezet akusztikai megfelelője a telefonsávon kívülre eső összetevőkben lenne található (vagyis mintegy 300 Hz alatt és 3300 Hz fölött).
A hetvenes évek végének kutatási eredményei szerint az alaphangmagasság majdnem elegendő kulcs az egyén hangjainak felismerésére (úgy vélték, hogy innentől már csak egy lépés magának a személynek az azonosítása). A pozitív eredménnyel zárult megkülönböztetési kísérletek hátterében azonban inkább a hallgatók jól működő rövid idejű memóriája állt, mint az alaphangmagasság mint egyértelmű felismerési tényező (Doehring–Ross 1972). Más kísérletek alapján azt gondolták, hogy a vokális traktus fontosabb a beszélő azonosításában, mint a larynxforrás (Hecker 1971). Ezek a laryngográfiás kísérletek is sikerrel zárultak; ismert személyek közül egy mondat alapján azonosították a kérdéses személyt. Valamennyi beszélő felismerése csak az alaphangmagasság alapján azonban csak 60–70%-os eredményt hozott.
Az akusztikai elemzések döntően a spektrográfián alapszanak; a következő paramétereket vizsgálják (különböző nyelvekben): formáns sávszélesség, központi formánsfrekvenciák, maximumpontok, a rés- és zárhangok zörejfrekvenciái, átmenetek és még valami, amit úgy neveznek, hogy „sajátos spektrográfiás alakzat”, de közelebbről nem meghatározható paraméter (Künzel 1995). Tekintetbe veendők még a beszédtempó, illetőleg az artikulációs sebesség, a hezitációs jelenségek és a dallammenet. A kutatók azonban egyetértenek abban, hogy a spektrogramok elemzése nem nyújt egyértelmű kulcsot a beszélő személy felismeréséhez. Az alapvető kiindulás mégis a beszéd akusztikuma. A Los Angelesben kifejlesztett beszélőazonosító rendszer (Nakasone–Melvin 1988) például 14 paramétert használ (az időtől a spektrumig). Ezzel a rendszerrel állítólag 98%-os pontosságot lehet elérni (a kísérletek 50 férfi beszélőtől származó beszédmintát tartalmazó adatbázison folytak).
A Hollien és munkatársai által kifejlesztett fonetikai alapú rendszer (SAUSI) olyan paramétereket használ az azonosításhoz, mint az F0, a csendes szünetek száma és hossza, a beszédtempó vagy a magánhangzók időtartama (Hollien 1990).
A leírtakból látható, hogy meglehetősen eltérőek a vélemények abban a tekintetben, hogy melyik a beszédnek az az összetevője, amelyik egyértelmű azonosítást tesz lehetővé. Az alaphangmagasság értéke, a formánsfrekvenciák, a beszédhang mikrointonációs szerkezete, a beszédhangok egymáshoz viszonyított intenzitása, a beszéd időszerkezete mind-mind olyan paraméter, amelyeket újra és újra meg kell vizsgálni az egyéni hangszínezet szempontjából. Azt vagy azokat a paramétereket kell megtalálnunk, amelyek mind a szegmentális, mind a szupraszegmentális szerkezetet tekintve, a legkisebb értékkel változnak, azaz közel állandó jelleggel reprezentálják a beszélő személy beszédét.
Több kísérletsorozatban vizsgálták a jelentés szerepét a beszélő felismerésében. Nem a nyelvi, stilisztikai sajátosságok tekintetében, a kérdés csupán az volt, hogy a szöveg érthetősége összefügg-e a beszélő személyének felismerésével. Az eredmények azt mutatják, hogy nem, a tartalom gyakorlatilag független a beszélő azonosításának sikerességétől (Janota 1967; La Riviere 1972; Schlichting–Sullivan 1998).
A fizikai értelemben jó minőséggel rögzített minták összehasonlítását a beszéd teljes spektrumában el lehet végezni. Jóval nehezebb feladatot jelent, ha az összehasonlítandó hangfelvételek rossz jel/zaj viszonyúak, és a kérdéses felvétel nem egységes telefonhálózaton belül készült. A minőségen kívül fontos a szerepe a minták időtartamának, az egységnyi időtartam alatt elhangzó információnak, valamint a szöveg spontaneitásának.
Állandóság és változás az artikulációban
A beszélőre jellemző neurális spektrogram nyilvánvalóan tartalmazza mindazokat a nyelvi/beszédbeli tényezőket, amelyek alapján azonosítjuk a személyt. Amennyiben ezt nem kérdőjelezzük meg, akkor valójában mi okozza az egyénre jellemző akusztikai tulajdonságok műszeres kimutatásának nehézségét? Elsősorban az, hogy a beszédinformációt továbbító akusztikus rezgések a hangképző rendszer tehetetlensége következtében kvázistacionárius jellegűek. Ez azt jelenti, hogy a rezgések paraméterei általában korlátozott ideig tekinthetők állandónak. Az előbbiekből következik, hogy a beszéd közben létrehozott hangsorok nem ismételhetők meg mégegyszer teljesen azonosan. Az 1. ábrán a Jó napot hangsor spektrogramja és hangsoron belüli intenzitásviszonyai láthatók ugyanazon személy ejtésében 1 nap eltéréssel. (A lehető legjobb, torzításmentes megjelenítés érdekében a hangsort 50000 minta/s-os mintavételezési sebességgel digitalizáltuk, és Hamming ablakfüggvényű 71 Hz-es szűrővel elemeztük.) Az ábra bal és jobb oldalának vizuális összehasonlítása alapján is megállapítható, hogy az időben később készült, jobb oldali hangfelvételről készült regisztrátumon a formánsok és az intenzitás értékei lényeges eltérést mutatnak.
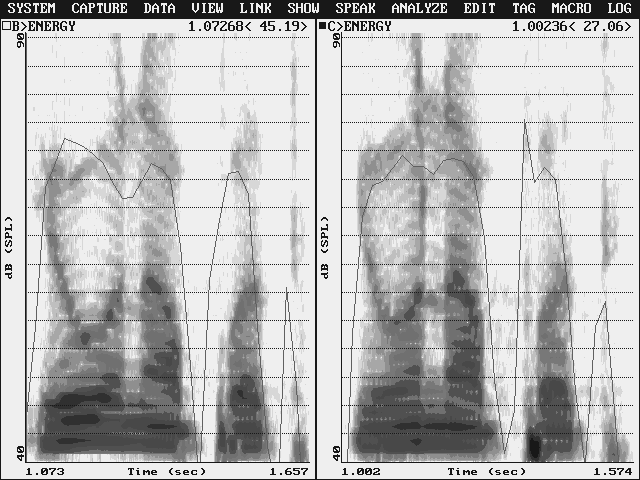
1. ábra
A Jó napot hangsor spektrogramja 0–3 kHz-es tartományban
A beszélő artikulációja tehát bizonyos mértékben változik, nagyon rövid idő elteltével is. Felmerül a kérdés, hogy mekkora lehet ez a változás, ha évek múlnak el. Tekintettel arra, hogy a jól ismert beszélőt még évek múltán is képesek vagyunk a hangja alapján felismerni, feltételezhetjük, hogy nem történnek döntő változások az artikulációs gesztusokban. A kérdésre kísérletsorozattal igyekeztünk választ kapni. Ugyanazon beszélő (nő) ugyanazon mondatáról készült hangfelvételt vizsgáltuk akusztikai-fonetikai szempontból hat év elteltével. A kontrollszemély egy hasonló életkorú nő volt. Az eredmények szerint az első formánsok szűk frekvenciatartományban realizálódnak, ennélfogva mindhárom beszélő (a vizsgált személy első (N1), hat évvel későbbi (N2) és a kontrollbeszélő (Nk) felvételének) adatai közel esnek egymáshoz. Valamivel nagyobb mértékű az azonosság, illetőleg az eltérés a második formánsok esetében: a kontroll beszélő F2-értékei jellegzetesen magasabb frekvenciatartományba esnek, mint a vizsgált személyé. A harmadik formánsok tekintetében ismét jellegzetesen alakuló képet látunk. Az ugyanazon beszélő formánsértékei tendenciájukban a 2900 Hz-es érték körül tömörülnek, míg a kontrollbeszélőé mintegy 100 Hz-cel alacsonyabb tartományba esnek.
A koartikulációs jelenségeket elemezve azt találták, hogy a magánhangzó típusa nem független az egyéni beszédjellemzők szempontjából; a hollandban például az [u] és az [a] szignifikánsnak bizonyult, az [i] azonban nem (Heuvel–Cranen–Rietveld 1995). Jellegzetesen alakulnak ugyanakkor az azonos fonetikai helyzetben előforduló magánhangzók időtartamai. Adataink azt mutatják, hogy N1 és N2 értékei alig különböznek, míg Nk időtartamarányai tendenciaszerűen különbözőek. Például az azonos helyen ejtett [i] magánhangzóra kapott időtartam N1 és N2 ejtésében: 63 ms, illetve 66 ms; Nk-é 51 ms; N1 és N2 ejtésében 59 ms, illetve 69 ms; Nk-nál 92 ms. Az [o] időtartama N1 és N2-nél 110 ms és 114 ms; Nk-nál 92 ms. A hosszú [o:] magánhangzóé N1 és N2-nél 123 ms, illetve 124 ms, míg Nk-nál 101 ms. Az [a:] időtartama N1 és N2-nél 108 és 118 ms, Nk-nál 86 ms; egy másik előfordulásban N1 és N2-nél 141 ms, illetve 146 ms, Nk-nál 126 ms. A zörejes réshangok akusztikai kulcsainak elemzési adatai szerint az ugyanazon beszélő alveoláris spiránsai nagyjából ugyanabban a frekvenciatartományban jelennek meg, míg a kontrollbeszélő teljes frekvenciaspektruma e mássalhangzókra eltérő képet mutat. Az alveoláris réshangok első intenzív zörejgóca alacsonyabb frekvenciaértéken jelentkezik a kontrollbeszélőnél, mint az ugyanazon beszélő esetében; másfelől a kontrollbeszélő vizsgált mássalhangzóinak zörejelemei gyakorlatilag a teljes frekvenciatartományban megjelennek, intenzíven még a 8 kHz táján is.
Elemeztük a rögzített beszédanyag felhangtartományát 50 és 1210 Hz között. Ebben az esetben tehát nem az egyes beszédhangok akusztikai kulcsait vetettük össze, hanem – a feltételezésünk szerint – az egyéni hangszínezetet jobban reprezentáló felhangszerkezetet. A kapott adatok a feltételezést alátámasztották: a felhangszerkezet a beszélő egyéni artikulációjának egyfajta jellegzetes lenyomataként jelentkezett. Vizsgáltuk (i) az intenzív felhangok frekvenciaértékeit, (ii) a felhangok frekvencialefutását az időben, (iii) a jellegzetes módosulásokat. Az ugyanazon beszélő ejtésében megvalósuló felhangszerkezet az alábbiakkal jellemezhető: (i) az intenzív felhangok 600–700 Hz-ig jelentkeznek, (ii) a frekvencialefutásra a meredek vonulat a jellemző (azonos hangidőtartamon belül), (iii) az intenzív felhangok kezdetén és/vagy végén rövid időtartamban bekövetkező hirtelen frekvenciaváltás látható. Ez a jellegzetes felhangszerkezet mind az első, mind a 6 évvel később rögzített ejtés alapján jelentkezik. A kontrollbeszélő felhangszerkezete ettől lényegesen eltér: (i) az intenzív felhangok 400–500 Hz-ig jelentkeznek, (ii) a frekvencialefutásra a fokozatos változás a jellemző, (iii) az intenzív felhangok hirtelen frekvenciaváltást nem tartalmaznak.
Az ugyanazon beszélő alapfrekvencia-értékei azonos tendenciát mutatnak, függetlenül az eltelt időtől. Az első ejtés alapján mért adatok a következők: 240 Hz-es csúccsal induló alaphang-görbe, amely fokozatosan csökken a közlés feléig 180 Hz-re, majd rövid szünetet követően ismét kisebb, 200 Hz-ről 230 Hz-re felfutó csúccsal, amely fokozatosan csökken a közlés végéig a 180 Hz-es értékre. A közlés teljes időtartama: 6877 ms. A hat évvel későbbi ejtés alapján mért adatok az alábbiak: 200 Hz-ről 230 Hz-re futó kis csúccsal indul az alaphanggörbe, amely fokozatosan csökken 170 Hz-re; rövid, néma szünetet követően 230 Hz-ről csökken fokozatosan 180 Hz-re. A közlés teljes időtartama: 7548 ms. A két közlés közötti tartambeli eltérés mindössze 671 ms, amely egy szótag időtartama. A kontrollbeszélő F0-görbéjének mért adatai a következők: kis csúccsal, 250 Hz-ről csökken az alaphang értéke a közlés harmadáig 200 Hz-re; ettől kezdve a frekvenciaérték nem változik, majd az utolsó harmad elején 20 Hz-es emelkedést követően enyhén csökken a görbe 190 Hz-re. A teljes energiatartomány elemzése is egyértelmű egyezést mutatott az ugyanazon beszélő ejtését tekintve; következésképpen jellegzetesen eltért a kontrollszemély ejtésétől.
Kimondható tehát, hogy az ugyanazon beszélő ejtése éveken át is stabil maradhat oly mértékben, hogy akusztikai-fonetikai következményeit elemezve, egyértelműen alkalmas a személy azonosítására. Az ellentmondás – hogy akkor a beszéd akusztikuma állandó vagy változó ugyanazon beszélő esetében – látszólagos. Ugyanazon személy artikulációs gesztusai kisebb eltérést mutatnak, mint egy másik személy ejtése (azonos szövegre vonatkozóan).
Kísérleti adatok
Több kísérletsorozatban vizsgáltuk a beszéd akusztikumát a hangszínezet egzakt meghatározása szempontjából.
1. Sajátos helyzetet választottunk, amikor valaki egy másik beszélőt személyesít meg azzal a határozott céllal, hogy a hallgatóban ezt a másik személyt idézze fel. Általában csak tudatos beszélők, rendszerint színészek képesek ilyen fajta utánzásra (a legkülönfélébb célokkal). Az utánzó tudatosan vagy kevésbé tudatosan igyekszik olyan artikulációs mozgássorokat létrehozni, amelyek hangzásukban a másik beszélőre jellemző beszédet képviselik. Nem arról van tehát szó egyszerűen, hogy az utánzó az utánozni szándékozott személy beszédprodukcióját imitálja, ez a sok tekintetben eltérő artikulációs szervek és működtetésük következtében nem is lenne lehetséges. Az utánzó az utánzott beszéd hangzását igyekszik megvalósítani a saját artikulációs bázisán belül a saját artikulációs mozgásainak részleges módosításával. Az utánzó helyzete azért is nehéz, mivel soha nem fogja úgy hallani az utánzott beszéd akusztikumát, ahogyan azt a hallgatóság, hiszen a beszélő a csontvezetés révén is dekódol. Mik az utánzó lehetőségei egy másik személy beszédének „reprodukálására”? Az átlagos alaphangmagasság közelítése, az egyénien ejtett beszédhangok felismerése és artikulációja, a sajátos beszéddallam és hangsúlyozás, valamint a beszédtempó utánzása.
Az utánzó fiziológiai alkata, beszédszerveinek morfológiai meghatározottsága, saját beszédének begyakorlottsága és tudatos működtetése különböző mértékben befolyásolják az utánzás sikerét. Nem véletlen, hogy az utánzások is eltérő mértékben hatásosak, az alig észrevehetőtől a feltűnően gyengéig. Mindez alapvetően függ a beszédet meghatározó objektív tényezőktől. A külső hasonlatosság (pl. arc, alkat) magában foglalhatja az artikulációs hasonlóságot is; ilyenkor az utánzónak könnyebb a dolga. Nem véletlen azon személyek kiválasztása, akiknek az utánzására valaki vállalkozik. Egyfelől olyan beszélőket választanak, akiknek a beszédét a saját beszédprodukciójukkal jól meg tudják közelíteni; másfelől igyekeznek a későbbi hallgatóság számára jól ismert beszélőket kiválasztani. Az „ismertség” nagyon fontos tényező; elengedhetetlen, hogy az utánzott személy beszédének akusztikai sajátosságai a hallgató „agyában” korábban már rögzítve legyenek.
Feltételeztük, hogy az utánzó és az utánzott személy beszéde akusztikailag nagyon hasonló kell, hogy legyen, hiszen ez eredményezi a hallgatóban a sikeres utánzás tényét. Ha ez a feltevésünk helyes, akkor meghatározhatók a beszédnek azok a komponensei, amelyek alapján a hallgató „becsapható”, vagyis az utánzó tökéletes. Ez egyúttal azt a kérdést is felveti, hogy mi a viszony az utánzó saját beszédének és az utánzottnak az akusztikai szerkezete között. A kérdések megválaszolásához többféle kísérletsorozatot folytattunk le.
Az első vizsgálatsorozat eredményeit az akusztikai elemzések adták. Ehhez az utánzást végrehajtó színész és az utánzott színész versmondását használtuk fel (az utánzó színész saját ejtésében is magnetofonszalagra mondta a verset). A felvételek laboratóriumi körülmények között folytak. Az elemzések során összesítettük a beszédhangok formánsaira, az időtartamokra, az alaphangmagasság és az intenzitás változásaira kapott értékeket, majd – ahol szükséges volt – statisztikai elemzéseket is végeztünk. Az egyes beszédhangokra vonatkozóan az összes lehetséges előfordulást adatoltuk (az azonos kontextus követelményét ennek ellenére sem tűzhettük célul minden esetben).
A beszédhangok akusztikai szerkezetének elemzése sajátos különbségeket, illetőleg egyezéseket mutat, egyfelől a beszélőtől függően, másfelől aszerint, hogy az utánzó utánozni kíván-e avagy „saját maga” beszél. A magánhangzók jellegzetesebbek, a mássalhangzók artikulációjában jellegzetes eltérés alig volt található. A magánhangzók közül az [e, ![]() , i] hangok első formánsai az utánzott színész ejtésében egyértelműen más frekvenciasávban realizálódnak, mint az utánzó esetében. Kisebb mértékű eltérések mutatkoznak a második formánsoknál is. Az utánzó színész kétféle ejtésében (saját és az utánzott) alig van különbség a beszédhangok első és második formánsának átlagértékei között. Az [
, i] hangok első formánsai az utánzott színész ejtésében egyértelműen más frekvenciasávban realizálódnak, mint az utánzó esetében. Kisebb mértékű eltérések mutatkoznak a második formánsoknál is. Az utánzó színész kétféle ejtésében (saját és az utánzott) alig van különbség a beszédhangok első és második formánsának átlagértékei között. Az [![]() ] magánhangzó különösen jellegzetesen alakul a háromféle ejtésben, ami azért sajátságos, mivel – lévén akusztikailag ún. „semleges” magánhangzó – nem feltételeztük, hogy jellegzetes különbség mutatkozzon a formánsok átlagértékeiben. Az adatok kismértékű eltérést mutatnak az utánzó (utánzott és saját) anyagában, és relatíve nagyfokú különbséget regisztráltunk az utánzó és az utánzott színész ejtése között (ezek az értékek félkövérítve vannak). Az első formáns átlagértékei az utánzó színész ejtésében: 498 Hz, 486 Hz, az utánzott színész ejtésében pedig 436 Hz, a második formáns átlagai ugyanebben a sorrendben: 1780 Hz, 1772 Hz és 1860 Hz.
] magánhangzó különösen jellegzetesen alakul a háromféle ejtésben, ami azért sajátságos, mivel – lévén akusztikailag ún. „semleges” magánhangzó – nem feltételeztük, hogy jellegzetes különbség mutatkozzon a formánsok átlagértékeiben. Az adatok kismértékű eltérést mutatnak az utánzó (utánzott és saját) anyagában, és relatíve nagyfokú különbséget regisztráltunk az utánzó és az utánzott színész ejtése között (ezek az értékek félkövérítve vannak). Az első formáns átlagértékei az utánzó színész ejtésében: 498 Hz, 486 Hz, az utánzott színész ejtésében pedig 436 Hz, a második formáns átlagai ugyanebben a sorrendben: 1780 Hz, 1772 Hz és 1860 Hz.
A többi magánhangzó esetében nagy értékkülönbségeket a háromféle ejtésben nem találtunk; a tendencia azonban kivétel nélkül megerősítette a három kiemelt beszédhangra jellemző eredményeket. Az utánzó imitált és saját eredeti artikulációja sokkal hasonlóbb, mint az imitált és az eredeti beszélőé. Lássunk néhány adatot! Az [a:] magánhangzó első formánsainak átlagértéke az utánzott színész (az érték félkövérítve), az utánzó és az utánzó eredeti ejtésében: 642 Hz, 660 Hz és 675 Hz. A második formánsok átlagértéke ugyanezen sorrendben: 1320 Hz, 1354 Hz és 1393 Hz. Hasonló a helyzet például az [e:] magánhangzó esetében is. Az első formánsok átlagértékei (az előző sorrendben): 368 Hz, 395 Hz és 414 Hz, a második formánsoké pedig 2018 Hz, 2068 Hz és 2087 Hz.
Elemeztük a harmadik formánsokat valamennyi mérhető helyzetben, az összes magánhangzónál. A statisztikai elemzések szignifikáns eltérést a háromféle ejtés alapján nem mutattak, a szórás a legtöbb esetben meglehetősen nagy volt. Az átlagértékek a következők (az eltérések 20–40 Hz körüli értékek, amelyek az F3 esetén jelentéktelenek): az F3 átlaga az utánzott színész ejtésében 2722 Hz, az utánzó ejtésében 2707 Hz, az utánzó saját ejtésében pedig 2683 Hz.
Az utánzott színész jellegzetesen artikulálja az [e] magánhangzót, lényegesen zártabban, mint a köznyelvben szokásos hangzás. E sajátosan zártan ejtett [e] magánhangzók első és második formánsának értékeit összegeztük. Az F1 átlaga 456 Hz, a második formánsé 1760 Hz. A „zártság” akusztikailag – a köznyelvi ejtés frekvenciájához képest – az első formáns értékének csökkenésében jelentkezik. Az utánzó ezt a zárt ejtést igyekszik megvalósítani, az ennek a módosított artikulációnak megfelelő akusztikai paraméterek az alábbiak. Az első formánsok átlagértéke 512 Hz, a második formánsoké 1720 Hz. Ezek az adatok azt mutatják, hogy a zárt ejtést közelíti ugyan az utánzó, de nem sikerül minden esetben ugyanolyan mértékben realizálnia azt (a köznyelvi ejtés – noha elég széles tartományban realizálódik – átlaga az első formánsra: 545 Hz).
Tudjuk, hogy – bizonyos korlátokkal – az artikulációs és a beszédtempó jellemző az egyénre. Sőt, éppen ez a Laziczius által „hangtulajdonságnak” nevezett tényező az, amelynek tudatos változtatására a köznyelvi beszélő alig képes. A gyakorlott utánzótól elvárható e tekintetben is a közelítés az utánozni kívánt beszéd eredeti időviszonyaihoz. Elemzéseink azt igazolták, hogy a beszédtempó alig, az artikulációs tempó adatai azonban szignifikánsan különböznek az utánzott színész és az utánzó beszédében. Ugyancsak szignifikáns különbséget találtunk az utánzó saját és utánzott beszédének időviszonyai között. Az egyes beszédhangok időtartamát a három szövegben a 2. ábra grafikonja szemlélteti. Az adatok szignifikáns eltérést mutattak (p<0.01 szinten) az utánzott színész és az utánzó ejtése között, amikor az utánzó a színész beszédprodukcióját imitálta.
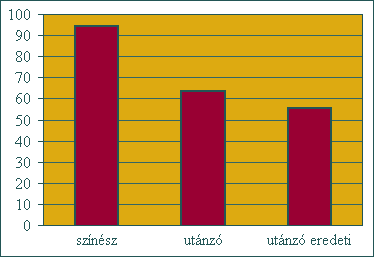
2. ábra
A beszédhangok átlagidőtartamának (ms) alakulása a három beszédanyagban
A mássalhangzók artikulációjában mindössze egyetlen jellegzetes eltérést tapasztaltunk az úgynevezett köznyelvi ejtésmódtól: az utánzott színész hehezetesen artikulálja a zöngétlen zármássalhangzókat, különösen abszolút szó végén. Ez az akusztikai képen egyértelműen jelentkezik: a zárfelpattanást követően alacsony intenzitású zörejelemek láthatók csaknem a teljes spektrumban, amelyek időtartama jóval meghaladja a magyar ejtésben normatívnak tekinthető értékeket. Megnéztük, hogy ez az ejtési sajátság miként érvényesül az utánzó artikulációjában. Saját ejtésében egyáltalán nem jelentkezik, vagyis a hehezetes zárhangokat nagyon tudatosan csak az imitált beszédben használja. A hallgató észlelésében az eredeti és az utánzott mássalhangzók azonosnak tűnnek. Meglepetésre, az akusztikai szerkezetük jellegzetes eltérést mutat. Amíg a színész ejtésében a hehezetesség a fent leírt struktúrát mutatja, addig az utánzó a kívánt hangzást egy nagyon intenzív zárfelpattanással „helyettesíti”. Az artikulációs mozgás tehát teljesen különböző, a hangzásélmény azonban nagyon hasonló.
Az ugyanazon beszélő artikulációs sajátosságainak állandósága – mint korábban tárgyaltuk – relatív; nehéz ugyanis azt megmondani, hogy milyen mértékű különbségek jellemzőek még ugyanazon beszélőre és melyek már nem. Nincs rendszeres vizsgálati adatmennyiség arra nézve sem, hogy vajon mely tényezők hatnak jobban vagy kevésbé a beszéd artikulációjára, s mely akusztikai paraméterek értékeiben érhetőek e változások tetten. Vizsgálati anyagunkban – még a szándékolt eltérés, azaz az utánzás ellenére is – a szavak akusztikai szerkezete sokkal nagyobb hasonlóságot mutat ugyanazon beszélő ejtésében, mint az eredeti és az utánzott ejtésű szavak esetében. A szegmentális akusztikai szerkezetek vizsgálata semelyik területen sem mutatott ki olyan jellegű egyezéseket (vagy különbözőségeket), amelyek a sikeres utánzást, illetőleg a hallgató benyomását kétséget kizáróan igazolták volna.
Ezt követően vizsgáltuk az alaphangmagasságot, valamint a beszéddallamok alakulását. Az utánzott színész alaphangmagasságának határértékei 107–155 Hz, az utánzóé pedig 103–140 Hz, vagyis az utánzó alaphangja kissé mélyebb. A színész utánzásakor az utánzó az alaphangmagasságát jellegzetesen megemeli, tehát közelít az utánzott beszélő értékeihez. Az utánzott beszéd F0-határértékei 125–150 Hz között szórnak. Az utánzó igyekszik továbbá az eredeti beszélő jellegzetes dallamvonulatait reprodukálni. Elemeztük az intenzitásváltozásokat. Az utánzott színészre jellemző, hogy nagy különbségekkel realizálja az egyes beszédszakaszokat. Az utánzó igyekszik az imitálás során ezt a hangerőstruktúrát megvalósítani. Helyenként túlzottan is él az intenzitás adta lehetőségekkel, nagyobb különbségeket hoz létre, mint amilyenek az eredeti beszélőnél tapasztalhatók. Ha összegezzük a szegmentális és a szupraszegmentális elemzések eredményeit, azt látjuk, hogy az utánzó egyre több területen és módon közelíti sikeresen az utánzott színészt; nem határozható meg azonban egyetlen vagy néhány olyan paraméter, amely(ek) egyértelműen felelős(ek) az észlelési élményért.
A következő kísérletsorozatban percepciós teszteléseket folytattunk. A résztvevőknek a különféle feladatokban azonosítaniuk vagy elkülöníteniük kellett a beszélőket, különböző hosszúságú hanganyagok alapján. A kísérleti személyek egy része jól ismerte az utánzott személyt, másik része nem. A tesztelések egy részében közöltük a résztvevőkkel az utánzás lehetőségét, a másikban nem. Választ igyekeztünk kapni arra az ellentmondásra, amelyet az objektív adatok és a szubjektív benyomás között tapasztaltunk. Ennek alapján a következő megállapításokat tehetjük.
(i) Tökéletesen sikeres a beszélő utánzása akkor, ha nincs azonos időben „versengő” beszédminta, vagyis ha az eredeti beszéd nem hangzik el az utánzást közvetlenül megelőzően. Ha a kísérleti személyek csupán az utánzót hallották, és azonosítaniuk kellett a beszélő személyt, akkor az utánzót az eredeti színészként ismerték fel 98,8%-ban. Az utánzó tehát képes volt a hallgatók „megtévesztésére”, ha aktuális összehasonlításra nem volt mód.
(ii) Ha csak differenciálni kellett az eredeti és a „másolat” között, vagyis rendelkezésre állt valamiféle „élő” minta is, akkor a hallgatók teljesítménye szignifikánsan javult, azaz az utánzás sikere szignifikánsan gyengült.
(iii) Az utánzás sikere nem volt független a hallott szöveg hosszától sem. Az eredeti beszélő biztonságos felismerése annál pontosabb, minél több beszédrészlet áll a hallgató rendelkezésére ahhoz, hogy az agyban tárolt „adatokat” az adott hangzásélménnyel összevesse. Minél több, illetőleg minél hosszabb a meghallgatott beszédrészlet, annál egyszerűbb a döntés. Kísérletünkben a szavak álltak szembe a mintegy mondatnyi hosszúságú beszéddel. Amikor a beszélőket a hallgatóknak szavak alapján kellett megkülönböztetniük, 43,4%-os téves eredményt kaptunk. A hibaarány 12%-ra csökkent, ha rövid szakaszok differenciálása volt a feladat.
Különösen nehéznek bizonyult a feladat, ha szavak alapján kellett a kísérleti személyeknek a három ejtést elkülöníteniük (a színészt, az utánzót és az utánzó eredeti szavait). Ebben a kísérletben közöltük ugyan a hallgatókkal, hogy ugyanazokat a szavakat fogják hallani egymást követően, de különböző beszélők kiejtésében. A szó elhangzása után azonnal dönteniük kellett a beszélő személyről. Aktiválniuk kellett a két beszélőhöz kapcsolódó neurális spektrogramokat, az aktuális felidézést segítő minta nélkül. Az eredmények határozott romlást mutatnak az előző kísérleti eredményekhez képest. A szavak azonosítása mindössze 33,2%-ban volt sikeres (ez szinte véletlenszerű találatnak tekinthető érték).
(iv) Azok a kísérleti személyek, akik nem emlékeztek jól az eredeti színészre, vagy ritkábban látták, hallották; érthetően gyengébb teljesítményt nyújtottak (ők főleg a fiatalabb korosztályokból kerültek ki).
Az akusztikai-fonetikai és a percepciós eredmények azt mutatják, hogy a beszéd utánozható, és a hallgató „átejthető”, ahogyan azt mintegy 200 évvel ezelőtt Kempelen Farkas megállapította a beszélőgépének építése kapcsán. Adataink azonban egyértelműen rávilágítottak arra is, hogy az utánzás sikere korlátozott, több tényezőtől függ, és rendkívül változékony. Az utánzó egyfelől közelíti saját ejtését az utánzott személyéhez, másfelől pedig mintegy felnagyítja, illetőleg még feltűnőbbé teszi az utánzottra jellemző ejtési sajátosságokat. E kettő kombinációjával éri el a kívánt hatást: azt, hogy nem ő, hanem valaki más, az a bizonyos személy beszél.
2. A következő kísérletsorozatban a felhangok személyazonosító funkcióját elemeztük a korábbi eredmények alapján. A formánsstruktúrát leválasztva, olyan felharmonikusokat keresünk, amelyek a legkevésbé esnek egybe (azaz megfelelő távolságban vannak) a formánshellyel. A formánshelytől távol levő felhang ugyanis a kívánt felbontással elemezve, magában hordozza a hangszalagrezgés egy teljes periódusában bekövetkezett változást. Ez az eltérés pedig spektrálisan megjeleníthető. Az így megjelenített, megfelelő számú spektrum összehasonlításával kialakítható egy olyan analizáló stratégia, amely rövid idő alatt nyújt értékelhető adatot, és jól reprezentálja a személy hangjának bizonyos sajátosságait.
A feltevés igazolására elvégzett kísérletben a beszédminta formáns- és felhangstruktúráját vizsgáltuk. A kísérlet első fázisában öt beszélővel végeztük el a vizsgálatokat úgy, hogy a kísérleti személyektől rendelkeztünk 23 évvel korábban készített hangfelvételekkel. A kiválasztott szöveget digitálisan rögzítettük. A rögzítés mintavételezési sebessége 50000 minta/s volt. A hanganyagból a kiválasztott hangot (ez az [l] mássalhangzó volt) szegmentáltuk. A megfelelő hosszúságú mintát (kb. 70 ms) keskeny sávú Hamming ablakfüggvénnyel 300 Hz sávszélességben szűrtük, majd az intenzitását többszörösen megnöveltük. A mintáról keskeny sávú spektrogramot készítettünk. A spektrogramok összehasonlításával a következő megállapításokat tehettük. A különböző személyektől származó zöngés mássalhangzók periódusonként más-más elhelyezkedésű intenzitásmaximumot mutatnak. A 3. ábrán látható, hogy a legfelső részben a periódusok gömbszerű alakot vesznek fel, lefelé mutató nyúlvánnyal, a középső részben elnyújtott formát láthatunk, felfelé mutató nyúlványokkal. Az alsó részben látható forma hasonlít ugyan a felsőhöz, de a gócok maximumpontjai felfelé mutatnak.
![Az [l] hang átlagosan nyolc periódusáról készült spektrografikus kép különböző személyek ejtésében](images/12340613.gif)
3. ábra
Az [l] hang átlagosan nyolc periódusáról készült spektrografikus kép különböző személyek ejtésében
Következtetések
A beszélő személy azonosítása a beszéde alapján már bizonyos múltra tekinthet vissza a magyar szakirodalomban (Gordos–Takács 1983; Gósy 1996; Nikléczy 1996), de rendszeres akusztikai-fonetikai és percepciós vizsgálata alig két éve indult meg. A munkálatok részlegesen ugyan támaszkodhatnak a nemzetközi szakirodalomban leírt eredményekre, a nyelvspecifikusság ténye azonban mindig új feladat elé állítja a kutatót. Az alábbiakban összegezzük azokat a megállapításokat, amelyek részben elméleti meggondolás, részben gyakorlati tapasztalat, illetőleg saját kísérleti eredményeink alapján már egyértelműen megfogalmazhatók. Ezek a megfogalmazható kijelentések nemegyszer sok-sok órás elemző munkán, számtalan adat sokféle feldolgozásán alapulnak (magukban foglalva a kutatás zsákutcáit is).
1. |
A beszéd akusztikuma oly mértékben jellemző a beszélőre, hogy az akusztikai-fonetikai paraméterek alapján a beszélő azonosíthatóvá válik. |
2. |
Az elméleti megállapítást a humán beszélőfelismerő képességünk is alátámasztja. |
3. |
A beszéd alapján történő közel objektív személyazonosítás számtalan tényező függvénye. Ezek részben külső faktorok (pl. a beszédrögzítési körülmények), és belsőnek tekinthetők (pl. a beszélő kooperációs készsége), amelyek befolyással vannak a felismerés biztonságára. |
4. |
A beszélőfelismerés során többféle eljárás is célravezető lehet; az alkalmazott módszert a konkrét cél, a beszédminta és egyéb körülmények határozzák meg. |
5. |
Jelenleg nincs tudományosan alátámasztott válasz arra vonatkozóan, hogy hány vagy mely paraméterek azok, amelyek az egyén felismerését kétséget kizáróan biztosítják. Nem zárható ki az, hogy az agyban tárolt neurális spektrogram aktiválása egészen különböző azoktól az akusztikai eljárásoktól, amelyek révén a beszéd egyéni jegyeit igyekszünk meghatározni. |
6. |
Ígéretesnek látszanak a felhangstruktúra elemzésének adatai. |
7. |
A beszélő személy felismerése multifaktoriális, azaz a hallgató a rendelkezésére álló valamennyi hangzásbeli, nyelvi, és ahol mód van, nem nyelvi információt is integrál az észlelési folyamata során a „feladat” elvégzéséhez. |
8. |
Különféle aspektusú akusztikai-fonetikai és percepciós kísérletek (és rengeteg adatfeldolgozás, -tárolás és összegzés) szükségesek ahhoz, hogy a probléma megoldásához közelebb jussunk. |
Mindezek után újra feltehető a kérdés: mit tud ma a fonetika a hangszínezetről. Elméleti aspektus ugyan, de fontos, hogy egyértelműen definiálható. A hangszínezet az elhangzó beszédnek az a jelensége, amely nagymértékben hozzájárul ahhoz, hogy a beszélő személy felismerhető. Mivel az ismert beszélőt telefonon át is azonosítjuk, a hangszínezet legjellemzőbb paraméterei a 200–3500 Hz-es sávban találhatók. A hangszínezet a beszéd akusztikumában van jelen, annak része; de összetett jelenség (nem korlátozható a zöngére), mivel minden valószínűség szerint több komponens hozza létre (beleértve a beszéd szegmentális és szupraszegmentális tényezőit egyaránt).
SZAKIRODALOM
Coulthard, M. 1992. Forensic discourse analysis. In: Advances in Spoken Discourse Analysis. Routledge. Ed.: Coulthard, M. London 242–58.
Crystal, D. 1985. A Dictionary of Linguistics and Phonetics. Blackwell. Oxford.
Doehring, D. G.–Ross, R. W. 1972. Voice recognition by matching to sample. J. of Psycholinguistic Res. 1. 233–42.
Doddington, G. R.–Helms, R. E.–Hydrick, B. M. 1976. Speaker verification III. Texas Instruments Inc. Report for RDAC, Rome, New York.
Gocsál Ákos 1998. Életkorbecslés a beszélő hangja alapján. In: Beszédkutatás ’98. Szerk.: Gósy Mária. MTA Nyelvtudományi Intézete. Budapest, 122–35.
Gordos Géza–Takács György 1983. Digitális jelfeldolgozás. Műszaki Könyvkiadó. Budapest.
Gósy Mária 1996. A beszéd akusztikai szerkezetének állandóságáról. In: Nyelv, nyelvész, társadalom. Emlékkönyv Szépe György 65. Születésnapjára barátaitól, kollégáitól, tanítványaitól. II. Szerk.: Terts István. Keraban Könyvkiadó. JPTE. Pécs, 66–75.
Gósy Mária–Nikléczy Péter 1999. A beszélő felismerése: elméleti megalapozás, módszertani közelítések. In: Beszédkutatás ’99. Szerk.: Gósy Mária. MTA Nyelvtudományi Intézete. Budapest, 1–19.
Hecker, M. 1971. Speaker recognition: an interpretative survey of the literature. A.S.H.A. Monogr. 16. Washington, D. C.
Heuvel, H. van den–Cranen, B.–Rietveld, T. 1995. Speaker characteristics in the coarticulation of three Dutch vowels [a, i, u.] Proceedings of the XIIIth ICPhS. Eds.: Elenius, K.–Branderud, P. KTH and Stockholm University. Vol. 2. Stockholm, 742–6.
Hollien, H. 1977. Speaker identification by long-term spectra under normal and distorted speech conditions. JASA 62. 975–80.
Hollien, H. 1990. The Acoustics of Crime. Plenum Press. New York, London.
Janota, P. 1967. Personal characteristics of speech. Trans. Of the Czechoslovak Academy of Sciences – Social Sciences Series 77/1.
Kempelen, W. von 1791. Mechanismus der menschlichen Sprache nebst der Beschreibung seiner sprechenden Maschine. Degen J. V. Wien.
Künzel, H. J. 1995. Field procedures in forensic speaker recognition. In: Windsor Lewis, J.: Studies in General and English Phonetics. Essays in Honour of Professor J. D. O’Connor. Routledge. London, 68–85.
Ladefoged, P. 1978. Expectation affects identification by listening. Language and Speech 21/4. 373–5.
La Riviere, C. 1972. Acoustic and perceptual correlates to aural speaker identification. In: Rigault, A. (ed.): Proc. 7th ICPhS. The Hague, 558–64.
Lux Gyula é. n., de 1926 után. A nyelv. Athenaeum. Budapest.
Molnár Imre 1942. Eufonétika. A szép beszéd és éneklés tana. Kis Akadémia kiadása. Budapest.
Nakasone, H.–Melvin, C. 1988. Computer assisted voice identification system. Proceedings IEEE-ASSP. 587–90.
Nikléczy Péter 1996. Beszélő személy azonosítása szűk frekvenciás szavak alapján. In: Beszédkutatás ’96. Szerk.: Gósy Mária. MTA Nyelvtudományi Intézete. Budapest, 20–31.
Nolan, F. 1995. Can the definition of each speaker be expected to come from the laboratory in the next decades? Proceedings of the XIIIth ICPhS. Eds.: Elenius, K.–Branderud, P. KTH and Stockholm University. Vol. 3. Stockholm, 130–4.
Regner Tivadar 1862. A magyar nyelv kiejtése. Magyar Akadémiai Értesítő II. Budapest.
Schlichting, F.–Sullivan, K. P. H. 1998. Can voice imitation be detected in voice line-ups in a language unknown by the listeners? Phonum 6. 105–18.
Schroder, M. R. (ed.) 1985. Speech and Speaker Recognition. Karger. Basel, München.
Stevens, K. N. 1998. Acoustic Phonetics. MIT Press. Cambridge, Mass..
Vértes O. András 1979. A hang némely tulajdonságának történeti változásáról. Magyar Fonetikai Füzetek 3. 42–8.
Vértes O. András 1980. A magyar leíró hangtan története az újgrammatikusokig. Akadémiai Kiadó. Budapest.
Gósy Mária
Gósy, Mária: Phonetic aspects of voice quality and speaker recognition. The paper starts with the definition of voice quality as one of those acoustic-phonetic properties of speech that are characteristic of the speaker. The author discusses various experimental and practical data concerning the theoretical, acoustic-phonetic and perceptual aspects of speaker recognition. The results of an experiment involving the imitation of another person’s speech, and the role of harmonics and related parameters are also discussed.
![]()
* A tanulmány a T0-25965. sz. OTKA-kutatás keretében készült.
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()