Hibaüzenet kezelése olvasáskor
Miért nem vesszük észre olvasáskor a hibásan írt (nyomtatott) szót? Hogyan nem vesszük észre a hibát?
A „hibátlan kézirat” problémájával régóta küszködik mindenki, s bármennyit „fejlődünk” is a gyakorlás és az évek során, mégis kevesen mondhatják el magukról, hogy betűhiba nélküli anyagot adhattak le. Mi lehet az oka annak, hogy nem vesszük észre az elírásokat, a második, sőt a harmadik olvasás után is maradnak nemkívánatos furcsaságok a szövegeinkben? Kézenfekvőnek látszik azt hinni, hogy figyelmetlenek vagyunk. Csakhogy ennek ellentmond az a mindannyiunk számára ismert tény, hogy mekkora erőfeszítéssel és odaadással, a külvilág szinte tökéletes kizárásával, általában nagy csöndben igyekszünk megoldani a lehetetlent, kijavítani a kéziratot, hibátlan korrektúrát produkálni. Ha a figyelmetlenséget kizárjuk, akkor a másik – gyakran hallott – okadó magyarázat a problémára az, hogy a szerző a saját szövegét már oly mértékben ismeri, hogy azt olvassa, amit leírni szándékozott, s így mintegy „átlép” az esetleges hibán. Ez talán közelebb jár a valósághoz, azonban ismét – bár nem kimondva – a figyelem tényezőjét állítja előtérbe. Ráadásul nem magyarázza meg azt, hogy miért nem vagyunk képesek akkor mások (tehát számunkra idegen) szöveg korrektúráját hibátlanul elkészíteni.
A választ és egyben a magyarázatot az olvasás folyamatában kell keresnünk (a modellekre vö. Ruddell–Ruddell–Singer 1994). Az olvasási folyamat két fő részre osztható, amellyel különösen jól modellálható a kezdő és a gyakorlott olvasó közötti különbség. Az első rész a dekódolás, vagyis a vizuális élmény alapján a betűsorok megfejtése, a betűknek a megfelelő beszédhangokkal történő megfeleltetése, a szó szegmentálása. A második részben történik a megértés: a szegmentált szó morfológiai struktúrájának felismerése és a jelentés azonosítása. Az olvasástanulás kezdetén a két részfolyamat egymásutániságban zajlik, gyakorlott olvasó esetén a dekódolási rész oly mértékben automatizálódik, hogy a vizuális inger hatására azonnal a szóstruktúra azonosítása zajlik (Samuels 1994a). Az újabb pszicholingvisztikai kutatások azt is igazolni látszanak, hogy nincs is minden esetben szükség arra, hogy a betűsort a beszédhangok sorozatának megfeleltessük. A vizuális inger képes azonnal aktiválni az olvasó mentális lexikonában a megfelelő egységet.
Hogyan történik tehát a szó felismerése olvasáskor? Az olvasó szemmozgása az írott szöveg felismerésekor két részből áll: gyors, előre menő (jelen esetben balról jobbra történő) mozgásból és az azt követő relatíve hosszú szünetből (fixálás), néha visszafelé mozgás is történik (jelen esetben balra vissza és ismét balról jobbra). A látás esetén egy pont fixálása olyan beállítódást jelent, amikor a pont képe mindkét szem recehártyáján a legjobb látás helyén jelenik meg. A szemmozgások nemcsak az olvasó gyakorlottságának függvényében változnak, hanem aszerint is, hogy az olvasott szövegnek mi a tartalma, milyen nehézségű és milyen céllal történik az olvasás.
Számos kutató állítja, hogy az olvasás gyakorlottságának következtében az olvasott betűk száma, illetőleg az észlelt szó nagysága (vagy a szavak száma) növekszik, mivel a percepciós átfogás (áttekintési képesség) nő (Gibson–Levin 1975; Haber 1978). Vizsgálták, hogy meghatározott időtartam alatt hány szót képes a kísérleti személy elolvasni. Az adatok szerint a kezdő olvasótól a gyakorlott olvasóig fokozatosan növekszik a percepciós átfogás mértéke: 7-8 éves gyermekek fél szót, felnőttek másfél szót olvastak egyetlen szemfixálás alatt (angol nyelvű kísérletek). Ezek az eredmények azonban azért nem egyértelműek, mivel az olvasás bizonyos fokú átfedéseiről nem adnak számot (előre is olvasunk, de újra is olvasunk, tehát visszamegyünk a szövegben). Tachisztoszkopikus kísérleteknél (ekkor egy előre meghatározott időtartamban villan föl a nyomtatott szöveg) 250 ms-onként adták a szövegeket a kísérleti olvasóknak (ez az érték nagyjából megfelel a szem fixálási idejének olvasáskor); s azt találták, hogy a gyakorlottabb, jobb olvasók több szöveginformációról tudtak beszámolni, mint a gyengébben olvasók (e módszer hátránya, hogy a retina működése következtében egy sor információ az olvasás és a hangos közlés folyamatában elvész). A szem átfogási képességének vizsgálatára szolgáló technikával (ún. szem-hang átfogás: a módszer több mint 100 éves, Quantz nevéhez fűződik (vö. Samuels 1994b: 363) azt elemzik, hogy hangos olvasáskor mekkora a „távolság” a kiejtett szó és a (szemmel) éppen dekódolt szó között. (Például lekapcsolják a villanyt egy adott szó kimondásakor, s megkérik a kísérleti személyt, hogy ejtse ki azokat a szavakat, amelyeket már elolvasott, de még nem tudott meghangosítani.) E módszer alkalmazásával ismét igazolták, hogy a gyakorlott, jó olvasóknak lényegesen szélesebb a vizuális átfogásuk, illetőleg, hogy több információt képesek befogadni és feldolgozni, mint a gyenge olvasók (vö. Morton 1964; Levin–Kaplan 1970). A mérési adatok szerint az olvasás meghangosítása általában két szemfixálásnyira marad el a vizuális feldolgozás mögött (ekkor azonban az átfedéseket, a szem jobbra és balra mozgásait nem vették figyelembe). A modern, számítógépes háttérrel megvalósított kutatások lényegében megerősítették a korábbi hipotéziseket és állításokat, igazolva például a vizuális aszimmetriát is.
Mindezek a kísérleti eredmények felvetették a szófelismerés vizuális egységének kérdését (hasonlóképpen a beszédészlelés, illetőleg beszédmegértés minimális egységéhez, vö. Gósy 1989). Sok évtizeddel ezelőtti adatok mutatják, hogy ugyanazon idő alatt különböző mértékű vizuális információt tudunk feldolgozni az adott szöveg nyelvi tartalmától függően. A jelentésnek meghatározó a szerepe: ugyanazon betű felismerése sokkal biztosabb szóban, mint izoláltan. A szemfixálás ideje alatt történik a betűsorozat egyedeinek felismerése, a sorozat alkotta egység (pl. szó) azonosítása, a jelentéshez való eljutás. Szövegolvasáskor természetesen a szövegkörnyezet is hat az egész olvasási folyamatra, a globális megértés következtében a kontextushatás éppúgy pozitívan érvényesül olvasáskor, mint beszédértéskor (könnyebb egy szót szövegkörnyezetben azonosítani, mint anélkül, akár hangzó beszédről, akár olvasásról van szó).
A kutatási eredmények alapján összegezhetjük, hogy a gyakorlott olvasónál (i) elsődlegessé vált a megértés, a vizuális dekódolási részfolyamatok kvázi-automatikusan, mondhatni nem tudatosan működnek, (ii) a szem átfogása relatíve széles, vagyis az olvasó akár több szó felfogására is képes (mindez nem független az adott nyelv szavainak szótagszámától, a toldalékolástól), (iii) a kontextuális hatás segíti és gyorsítja a mentális lexikon aktiválását és a megfelelő egység „lehívását”. Mindezek a tények pedig együttesen idézik elő azt, hogy a hibaüzenetet nem veszi az olvasó, ugyanis a megértési részfolyamatok felülbírálják az elsődlegesen működő dekódolási, szóészlelési folyamatokat. Ez azt jelenti, hogy a dekódolás feltehetően jól működik, de a ráépülő szemantikai tényezőkkel megtörténik az önkéntelen korrekció. Vegyük azt a példát, hogy: Énekes madaraktól zeng az erdű, ahová kirándultunk. Különösen, ha hosszabb szövegbe ágyazva találkozunk ezzel a mondattal, jó esélyünk van arra, hogy az erdő szó hibás betűsorozatát ne vegyük észre. Hiába történik meg a szóvégi ű betű pontos észlelése, a folyamat egy magasabb szintjén már a szükséges ő betűvé korrigálódik, azáltal, hogy a szóértés megtörtént. Nem a hibás betű cseréje zajlott le a szükséges betűre, hanem az aktivált jelentés a megfelelő betűsorozatot tartalmazta.
Kísérletet terveztünk és folytattunk le a fentebbi megállapítások ellenőrzésére, illetőleg számos további kérdés megválaszolására. Melyek azok a hibatípusok, amelyeket nem tudunk kezelni; a vizuális feldolgozási stratégiának, a nyelvi jelnek vagy milyen egyéb tényezőnek van szerepe a hibaüzenetek kétértékű kezelésében?
A kísérlet anyagát egy napi politikai tartalmú újságcikk adta (cím: Konfliktusok is vállalhatók, betűnagyság: 11 pontos, homogén álló betűk, 42 sor az oldalon, négy bekezdéssel). A szöveget számítógépre vittük, a bevitel során – szándéktalanul – 17 elírás (ti. géphiba) keletkezett; ezeket érintetlenül hagytuk, és további 33 mesterséges hibát tettünk a szövegbe. Végeredményként a szándéktalan és a tervezett elütések nyomán előálltak a jellegzetes, illetőleg a célunkhoz szükséges hibatípusok. Ügyeltünk arra, hogy a géphibák az oldalon nagyjából egységesen oszoljanak el, forduljanak elő szó és mondat elején, közepén és végén. A szöveg tartalmához öt ún. megértést ellenőrző kérdést állítottunk össze. A kísérleti személyek 25 és 35 év közötti főiskolát végzett, magyar szakos tanárok voltak, összesen harmincan (többségük nő). Az előzetesen közölt feladatmegjelölés szerint el kellett olvasniuk a szöveget úgy, hogy közben aláhúzással jelöljék az esetleges hibákat. A tartalomra is figyelniük kellett, mivel tudták, hogy a szövegértést is ellenőrizni fogjuk. Az utasítás nem szólt a hibák számáról vagy típusáról. Azt kértük, hogy csak egyszer olvassák el a szöveget, azonban sietniük nem kellett (aki készen volt, megfordította a lapot). A kísérleti személyek 12 és l6 perc között olvasták el az oldalt, és javították a hibákat. Ezt követően a lap másik oldalán a hangosan feltett kérdésekre egyenként kellett rövid írásos választ adniuk.
Az eredmények számos meglepetéssel szolgáltak. „Elvárásunknak” megfelelően nem volt olyan kísérleti személy, aki az összes hibát megtalálta volna, a legjobb eredmény 90%-os volt, ez a személy az 50 hibából 45-öt azonosított. A legtöbben 70% és 88% közötti eredményt értek el (összesen huszonegyen), négyen 64% és 68% között teljesítettek, a leggyengébb olvasó a hibáknak csupán 22%-át fedezte fel. Az összes résztvevő hibafelismerési átlaga 73,9%. Ez az érték arra is utal, hogy a javításhoz nem szokott olvasó ennél jóval több hibát nem azonosít, míg egy gyakorlott kiadói korrektor feltehetően jobb teljesítményre képes. A szöveg szándéktalan és szándékos elgépeléseit hatféleképpen csoportosítottuk: betű betoldása a szóba (pl.: ameelyek, társadadlombiztosítás), betűhiány a szóban (pl.: kérdékört, polgárainkal), betűcsere a szóban (pl.: vélemányét, progtamjának), betűmetatézis a szóban (pl.: foyltatott, felevtések), helyesírási hiba (pl. irás) és ún. tartalmi hiba, amikor egy betűben eltérő, de értelmes szó állt az eredeti szó helyén (pl.: eligazítás az eligazítást helyett vagy eljárásuk az eljárásunk helyett). A különböző hibák esetenként helyesírási hibákká is alakultak, például a polgárainkal szó betűhiánya következtében létrejött helyesírási hiba. Ezeket külön is elemeztük. Az 1. táblázat az egyes hibatípusok szerint összegzi az adatokat.
1. táblázat: A hibák felismerése típusok szerint
|
Az eltérések jellegzetesek, ha piramisszerűen ábrázoljuk az adatokat, akkor megkapjuk a hibák felismerhetőségi sorrendjét (a piramis alján a könnyen, egyre feljebb jutva a nehezebben felismerhető hibatípusokat látjuk) (1. ábra).
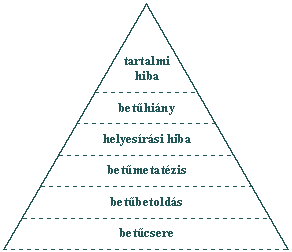
1. ábra
A hibafelismerési piramis
Elemeztük a hibafelismerést aszerint, hogy a hiba hol helyezkedett el a szóban. Nem túlzottan nagyok, de jelentősek a különbségek: legkevésbé a szó elején előforduló hibák azonosíthatók (72,3%), majd a szóvégiek (82,6%), leginkább észrevehetőek a szóközepiek (86%). További vizsgálatra szorul, de elképzelhető, hogy ez összefügg a magyar szavak morfológiai felépítésével, illetőleg a fixálás helyével. Szignifikánsan jobb a hiba felismerése, ha szótaghatáron vagy szóhatáron fordul elő, például összetett szóban. A kérdékört szó hibáját 96,6%-ban megtalálták, míg a kédéskörét szóét csupán 63,3%-ban. Legkevésbé feltűnő a hiba, ha mássalhangzó-torlódásos helyzetben hiányzik vagy toldódik be egy betű; a stukturális szóban a kísérleti személyek csupán 36,6%-a vette észre a hiányt. Ugyanakkor igen jó a felismerési aránya például azoknak a betűhiányoknak, amelyek magánhangzó-kapcsolatot eredményeznek. Feltételeztük, hogy a szavak gyakorisága is valamilyen mértékben hatással van a hibaüzenet kezelésére. A kérdés az, hogy vajon a gyakrabban látott szó olvasata automatikusabb, vagy éppen ellenkezőleg, a mélyebben bevésődött betűsorozat jobb hibafelismerést eredményez. Anyagunk alapján azért nehéz erre egyértelműen választ adni, mivel nincsenek objektív ismereteink arról, hogy a kísérleti személyeknek mint csoportnak mely szavak jelenthettek gyakori olvasatút és melyek ritkábbat. Tételezzük fel tehát a közös, pedagógiai háttér alapján, hogy gyakran olvasott szavak például a válaszol, kérdés, tenni vagy mellett. Az ezekben a szavakban lévő hibát a kísérleti személyek 80-90% között találták meg. A ritkábbnak tartott mezőgazdálkodók, strukturális vagy Finnország szavak hibaüzenetének kezelése lényegesen gyengébb, 30-70% közötti volt.
Ellenőriztük, hogy az olvasás irányának van-e hatása a hibafelismerésre. A szöveget függőleges vonalakkal három egyenlő területre osztottuk, s megnéztük, hogy az egyes területekre kerülő hibák átlaga mutat-e eltérést. A legkevésbé észrevehetőek a szövegoldal közepén előforduló hibák (69,5%), valamivel jobban azonosíthatóak a bal szélre esők (72,2%), és legnagyobb eséllyel a jobb szélre esők fedezhetők fel (82,7%).
A szövegértés eredménye rendkívül gyenge volt. A kísérleti személyek egy része utólag úgy nyilatkozott, hogy képtelen volt a tartalomra figyelni, mert lekötötte a hibakeresés. Az összes résztvevőt és mind az öt kérdést figyelembe véve a helyes válaszok átlaga 30%, vagyis a kísérleti személyek alig-alig értették meg az olvasottakat! Hatan közülük egy kérdésre sem voltak képesek válaszolni, s csupán egyetlen pedagógus akadt, aki az ötből négy kérdésre jól válaszolt. A legtöbben két-három kérdésre adtak elfogadható feleletet. Megnéztük, hogy milyen összefüggés mutatható ki a felismert hibák száma és a megértés között. Kimondható, hogy minél több hibát azonosít a kísérleti személy, annál kevésbé tudja a szöveg tartalmát követni. Ebben az esetben tehát tudatosan összpontosít az olvasás technikai, vagyis dekódolási részére, s ez megakadályozza a „magasabb szintű” nyelvi feldolgozó folyamatok megfelelő működtetésében. A 2. ábra a hibafelismerés és a helyes szövegértés összefüggéseit ábrázolja.
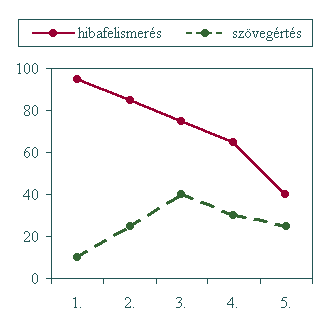
2. ábra
A hibafelismerés és a szövegértés százalékos összefüggése
(az öt csoportot a hibafelismerési átlagok alapján alakítottuk ki)
A hibaüzenet és az értés között tapasztalt összefüggés választ ad arra is, hogy az ún. tartalmi hibák miért kerülik el nagymértékben az olvasók figyelmét. A „tartalmi hiba” lényege az, hogy – bár elírás okozza a hibás formát – a létrejött szó értelmes marad. Ha az olvasó a „hibaüzenetre” igyekszik koncentrálni, akkor ezek a szavak különösen nem lesznek feltűnőek. Ha a hibakereséstől függetlenül az olvasó jobban figyel a szöveg tartalmára, akkor természetesen ezeket a hibákat is megtalálja.
Az olvasás folyamatának természetes működése már önmagában magyarázattal szolgál a hibaüzenetek részleges kezelésére, vagyis arra a mintegy 30%-nyi észre nem vett hibás formára, ami bent marad a szövegben. A gyakorlott olvasó automatikus és relatíve gyors dekódolási működései már nem teszik lehetővé a betűsorok pontos, szeriális azonosítását. Az ebben az értelemben „részlegesen” működő folyamatra épül az értő olvasás, vagyis nem a k + ö + (n + y) + v + e + i + t + e + k + r + ő + l betűsort, hanem csaknem azonnal a [’tietek’ + sok + ![]() + ’ról/ről’] tartalmat (jelentésegységet) értjük meg. Az írott (nyomtatott) szavaknak egyfajta engramja alakul ki az agyban az olvasás során; vizuális észleléskor az olvasó globális megfelelést végez a tárolt engrammal. Különösen jól tapasztalható ez a toldalékmorfémák olvasásakor, amelyek előjelzése a grammatikai szerkezetek következtében aktuális olvasás nélkül is nagy valószínűséggel sikeresen elvégezhető.
+ ’ról/ről’] tartalmat (jelentésegységet) értjük meg. Az írott (nyomtatott) szavaknak egyfajta engramja alakul ki az agyban az olvasás során; vizuális észleléskor az olvasó globális megfelelést végez a tárolt engrammal. Különösen jól tapasztalható ez a toldalékmorfémák olvasásakor, amelyek előjelzése a grammatikai szerkezetek következtében aktuális olvasás nélkül is nagy valószínűséggel sikeresen elvégezhető.
Szükség esetén, például korrektúra olvasásakor, az olvasó megpróbál a betűsorra összpontosítani. Ez azt jelenti, hogy, bár nem tudatosan, de csökkenti a dekódolási műveletek automatikusságát. Ennek két következménye van, egyfelől az, hogy maga az olvasás lassúbb lesz, másfelől a tartalom követése válik nehezebbé. Gyakrabban fordul elő a sorok (szavak, mondatok) újraolvasása; nemegyszer a második olvasat felel meg az értő olvasásnak. Gyakorlással a „korrektúraolvasás” technikája fejleszthető. Minél rövidebb az olvasandó szöveg, annál nagyobb a valószínűsége, hogy nagy számban vesszük a hibaüzeneteket; a fáradás az olvasásnak ebben a formájában sokkal előbb következik be, mint normális körülmények között.
Befejezésül, röviden összegezzük azokat a tényeket, amelyek tudatos ismerete segítséget jelenthet a hibák mind nagyobb számú megtalálásához. A tartalomra figyelés csökkenti az elírások észrevehetőségét; legnehezebb az olyan hibák felismerése, amelyek értelmes szavakat eredményeznek; a betű hiánya kevésbé feltűnő, mint a többlet betű; a mássalhangzó hiánya két magánhangzó között feltűnőbb, mint a magánhangzó hiánya; a szavak elején és végén előforduló tévesztések nehezebben azonosíthatók, mint a szó közepén lévők; szóhatáron könnyebben szembesülünk a hibával, mint szótaghatáron vagy mássalhangzó-torlódáskor; a lap jobb oldalán könnyebben észrevesszük az elírásokat, mint a lap bal oldalán vagy közepén előfordulókat. Nem véletlen, hogy a helyesírási hibát eredményező tévesztéseket valamivel jobban azonosítjuk, mint azokat, amelyek „csak” géphibának minősülnek. A további kutatásnak arra kell irányulnia, hogy miképpen teszi lehetővé az olvasás bonyolult folyamata azt, hogy sokszor felismerjük az elírásokat akkor is, ha nem keressük azokat tudatosan.
SZAKIRODALOM
Gibson, E. J.– Levin, L. A. 1975. The Psychology of Reading. MIT Press. Cambridge, MA.
Gósy Mária 1989. Beszédészlelés. MTA Nyelvtudományi Intézete, Budapest.
Haber, R. N. 1978. Visual perception. Annual Review of Psychology 29: 31–59.
Levin, H.–Kaplan, E. L. 1970. Grammatical structure and reading. In: Levin, H.–Willima J. P. (eds.): Basic Studies on Reading. Basic. New York, 75–96.
Morton, J. 1964. The effects of context upon speed of reading, eye movements, and eye-voice span. Quarterly Journal of Experimental Psychology 16: 340–54.
Ruddell, R. B.–Ruddell, M. R.–H. Singer (eds.) 1994. Theoretical Models and Processes of Reading. International Reading Association. Newark.
Samuels, S. J. 1994a. Toward a theory of automatic information processing in reading. In: Ruddell, R. B.–Ruddell, M. R.–H. Singer (eds.): Theoretical Models and Processes of Reading. International Reading Association. Newark, 816–38.
Samuels, S. J. 1994b. Word recognition. In: Ruddell, R. B.–Ruddell, M. R.–H. Singer (eds.): Theoretical Models and Processes of Reading. International Reading Association. Newark, 359–381.
Gósy Mária
Gósy, Mária: On the difficulties of proofreading. Difficulties of proofreading are rooted in the subprocesses of the reading mechanism. This paper deals with those factors that provide an opportunity for identification or, in the contrary, block the identification of the typing errors when reading a text. Results based on experimental data show that exchange, insert and metathesis of the letters can be relatively easy to detect, however, identification of the orthographic mistakes and the lack of letters is more difficult. The most difficult type of mistakes to be found is the so-called ’content error’ when the typing error results in a meaningful word.
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()